flowchart LR
CPU[CPU] --- Bus[(Bus del sistema)]
RAM[Memoria<br>RAM] --- Bus
Bus --- C1[Controlador<br>de disco]
Bus --- C2[Controlador<br>USB]
Bus --- C3[Controlador<br>de red]
C1 --- D1[Disco]
C2 --- D2[Teclado]
C3 --- D3[Tarjeta<br>de red]
7 Gestión de la Entrada y Salida (E/S)
La gestión de la entrada y salida (input/output, E/S) es la disciplina que permite al sistema operativo coordinar el intercambio de datos entre la CPU, la memoria y los dispositivos externos: discos, redes, teclados, pantallas, impresoras y muchos más. A diferencia de la CPU y la memoria, los dispositivos de E/S son extraordinariamente heterogéneos en velocidad, formato y comportamiento; el SO debe ofrecer una interfaz uniforme que oculte esa diversidad a las aplicaciones.
7.1 Objetivos de Aprendizaje
- Comprender los conceptos introductorios de la E/S y la clasificación de los dispositivos en orientados a carácter y orientados a bloque.
- Identificar los componentes de hardware involucrados en la E/S: controlador, puerto y bus.
- Distinguir los mecanismos de polling, interrupciones y DMA, y reconocer cuándo conviene cada uno.
- Describir la interfaz entre las aplicaciones y la E/S a través de las llamadas al sistema (
read,write,open,close). - Comprender el rol del scheduling de E/S en el sistema operativo.
- Diferenciar buffering, caching y spooling como técnicas de manejo de datos en memoria para la E/S.
- Conocer a nivel conceptual los algoritmos de scheduling de disco: FCFS, SSTF, SCAN, LOOK y C-SCAN.
7.2 Conceptos Introductorios de la E/S
Cualquier sistema de cómputo útil debe comunicarse con el mundo exterior: leer del teclado, mostrar en pantalla, guardar en disco, enviar por red. Toda esa actividad se llama genéricamente entrada y salida (E/S). El sistema operativo es el responsable de gestionarla porque dos hechos lo hacen imprescindible:
- Los dispositivos son mucho más lentos que la CPU. Un acceso a disco mecánico tarda milisegundos; la CPU ejecuta millones de instrucciones en ese mismo intervalo. Sin un intermediario que coordine la espera, la CPU perdería todo su tiempo aguardando.
- Los dispositivos son enormemente diversos. Cada uno tiene su protocolo, su velocidad, sus tamaños de bloque y su modo de fallo. El SO ofrece una interfaz uniforme (
read,write,open,close) que oculta esa diversidad a las aplicaciones.
7.2.1 Clasificación de los dispositivos: carácter y bloque
Una clasificación útil divide los dispositivos según la unidad mínima con la que el SO intercambia datos:
| Tipo | Unidad de transferencia | Acceso | Ejemplos |
|---|---|---|---|
| Carácter | Un byte (carácter) por vez | Secuencial | Teclado, ratón, puerto serie, impresora antigua |
| Bloque | Bloque de tamaño fijo (típ. 512 B o 4 KB) | Aleatorio (cualquier bloque) | Disco rígido, SSD, CD-ROM, memoria USB |
Tabla 1: Dispositivos orientados a carácter vs. orientados a bloque.
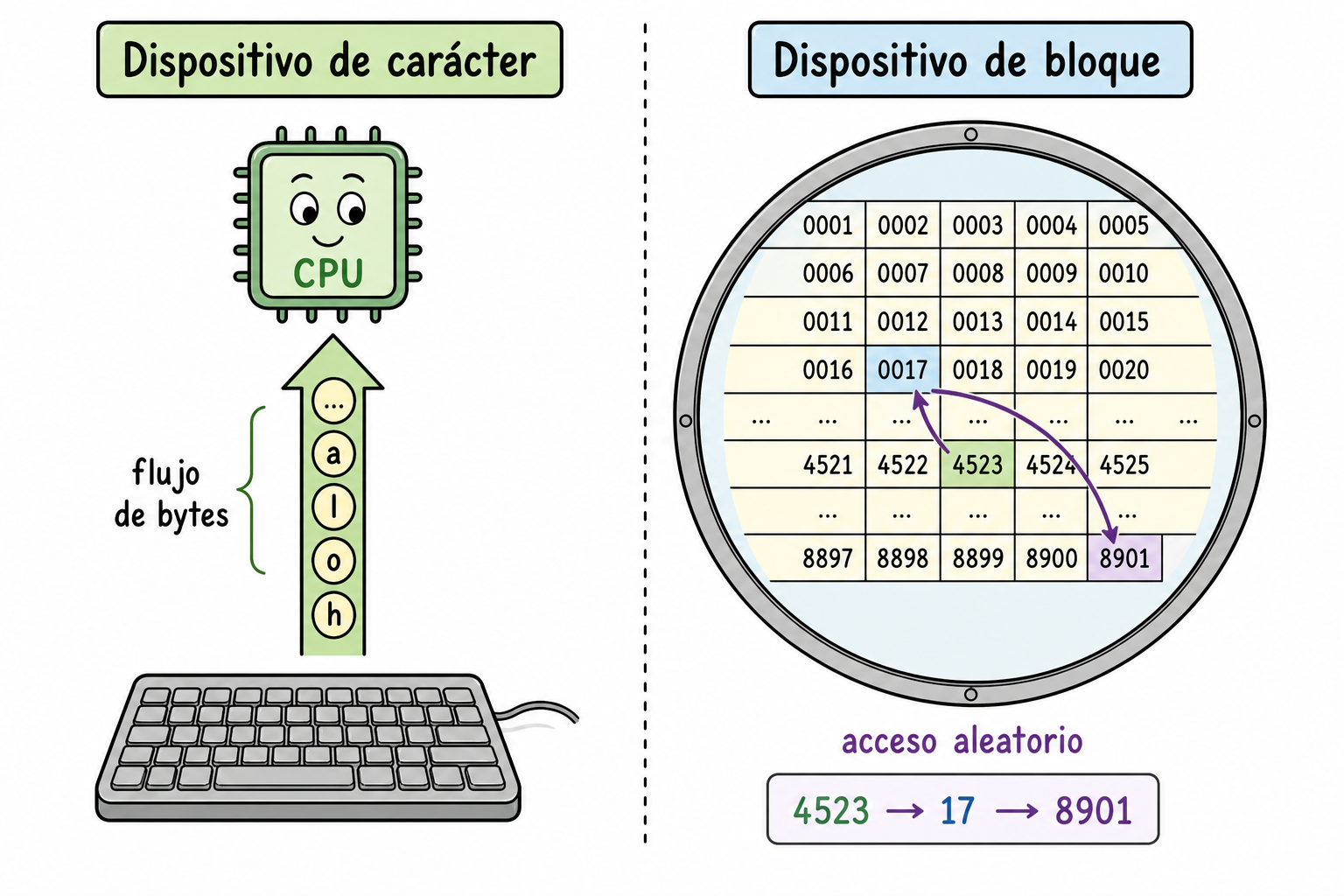
Los dispositivos de carácter entregan o reciben un flujo de bytes en orden; el SO no puede pedir “el byte número 1000” directamente. Los dispositivos de bloque sí permiten acceso aleatorio: el SO puede leer el bloque 4523 sin tocar los anteriores. Esta distinción afecta cómo se diseña el driver y qué optimizaciones aplican (caching y scheduling tienen sentido sobre todo en dispositivos de bloque).
Note
Idea clave. Linux y Unix exponen esta clasificación en /dev: los archivos con c en sus permisos son dispositivos de carácter; los que tienen b, de bloque. Ejecutando ls -l /dev/sda /dev/tty se ven ambos tipos lado a lado.
7.3 Hardware de E/S: Controlador, Puertos y Buses
Para comprender cómo el SO controla un dispositivo es indispensable conocer el hardware intermedio. Tres conceptos lo describen: controlador, puerto y bus.
7.3.1 Controlador
El controlador de dispositivo (device controller) es un chip o tarjeta electrónica que opera un dispositivo concreto y le habla a la CPU en un lenguaje estándar. Cada tipo de dispositivo tiene su propio controlador: hay controladores SATA para discos, controladores USB, controladores Ethernet, controladores de tarjeta de video. La CPU nunca habla directamente con el dispositivo: siempre pasa por su controlador.
7.3.2 Puertos de E/S
Un puerto de E/S (I/O port) es un conjunto de registros del controlador que la CPU usa para comunicarse con él. Típicamente cada controlador expone:
- Registro de datos: por donde entran o salen los bytes a transferir.
- Registro de estado: indica si el dispositivo está listo, ocupado o tuvo error.
- Registro de control: recibe órdenes (leer, escribir, reset, etc.).
La CPU lee y escribe estos registros con instrucciones especiales (en x86, in/out) o mapeándolos en direcciones de memoria reservadas (memory-mapped I/O).
7.3.3 Bus
El bus es el conjunto de líneas físicas y eléctricas que transportan datos, direcciones y señales de control entre la CPU, la memoria y los controladores. Buses comunes hoy: PCI Express (placas internas), USB (dispositivos externos), SATA y NVMe (almacenamiento).
Figura 1: La CPU se comunica con cada dispositivo a través de su controlador, conectados por un bus común.
Tip
Analogía. Pensemos en un edificio de oficinas. La CPU es el director general; los dispositivos son los empleados con tareas especializadas. Cada empleado tiene un asistente (controlador) que recibe las órdenes en formato estándar y traduce al lenguaje particular del empleado. El pasillo (bus) es por donde circulan los memos. El director nunca camina hasta cada escritorio: deja la orden con el asistente y sigue trabajando.
7.4 Polling, Interrupciones y DMA
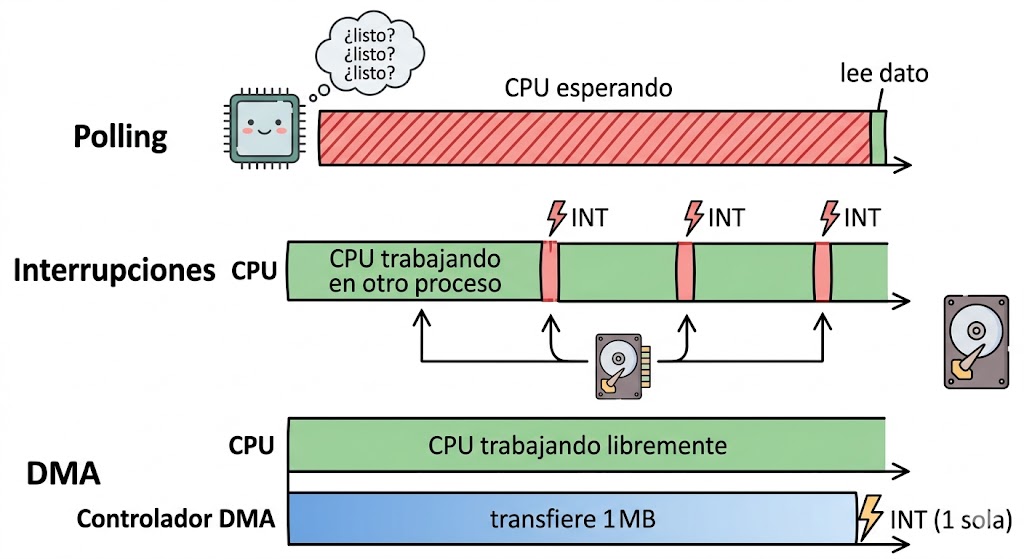
¿Cómo se entera la CPU de que un dispositivo terminó su trabajo? Hay tres mecanismos históricamente importantes, en orden de eficiencia creciente: polling, interrupciones y DMA.
7.4.1 Polling
En el esquema de polling (sondeo), la CPU pregunta repetidamente al controlador “¿estás listo?” leyendo su registro de estado en un bucle. Mientras el dispositivo no termina, la CPU sigue preguntando.
while ((leer_registro_estado(disco) & BIT_LISTO) == 0) {
// espera activa: no hace nada útil
}
leer_registro_datos(disco);Es simple y útil cuando el dispositivo responde casi de inmediato, pero derrocha ciclos si la espera es larga: la CPU está ocupada sin avanzar trabajo real.
7.4.2 Interrupciones
Con interrupciones, la CPU lanza la operación al controlador y sigue con otra tarea. Cuando el dispositivo termina, su controlador eleva una señal eléctrica —la interrupción— que obliga a la CPU a pausar lo que está haciendo, ejecutar una rutina de atención (Interrupt Service Routine, ISR) y luego volver a su trabajo previo.
Ventajas claras sobre polling:
- La CPU no pierde tiempo preguntando.
- Permite multiprogramación: mientras un proceso espera E/S, otro puede ejecutar.
- Escala a muchos dispositivos: cada uno tiene su línea de interrupción asignada.
7.4.3 DMA (acceso directo a memoria)
Las interrupciones evitan la espera ociosa, pero la transferencia de los datos sigue pasando byte por byte por la CPU. Para mover un megabyte del disco a la memoria, la CPU copiaría un millón de bytes uno por uno. El acceso directo a memoria (Direct Memory Access, DMA) resuelve esto.
Un controlador de DMA es un chip auxiliar capaz de mover datos directamente entre el dispositivo y la RAM, sin que la CPU intervenga byte por byte. La secuencia típica:
- La CPU le indica al DMA: “copiá 1 MB del disco a la dirección de memoria X”.
- La CPU sigue ejecutando otros procesos.
- El DMA realiza la transferencia completa.
- Al terminar, el DMA dispara una sola interrupción a la CPU.
Ejemplo numérico. Transferir 1 MB en bloques de 4 KB significa 256 transferencias.
- Con interrupciones tradicionales: 256 interrupciones, una por bloque.
- Con DMA: 1 interrupción total, al finalizar todo el megabyte. La CPU queda libre durante la transferencia.
7.4.4 Comparativa
| Mecanismo | CPU durante la espera | Costo | Cuándo conviene |
|---|---|---|---|
| Polling | Bloqueada en bucle | Mínimo (sin hardware extra) | Dispositivos muy rápidos o sistemas embebidos simples |
| Interrupciones | Libre para otros procesos | Hardware de interrupciones + ISR | Dispositivos lentos o esporádicos |
| DMA | Libre durante toda la transferencia | Controlador DMA | Transferencias de bloques grandes (disco, red, audio/video) |
Tabla 2: Mecanismos de notificación y transferencia en E/S.
Important
Idea clave. Interrupciones liberan a la CPU de esperar; DMA la libera además de transferir. Combinados, permiten que un sistema moderno ejecute miles de operaciones de E/S por segundo sin sacrificar el avance de los procesos de usuario.
7.5 Interfaz entre la Aplicación y la E/S
Las aplicaciones nunca tocan controladores ni puertos directamente: hablar con el hardware es privilegio del kernel. La aplicación pide un servicio mediante una llamada al sistema (system call), el kernel la atiende y devuelve el resultado.
7.5.1 El modelo “todo es un archivo” de Unix
Unix unificó la E/S bajo una idea radicalmente simple: todo dispositivo se manipula como un archivo. La aplicación abre un archivo, escribe bytes, lee bytes y lo cierra. No importa si detrás hay un disco, un teclado, un socket de red o una impresora.
Las cuatro llamadas al sistema fundamentales son:
| Llamada | Función |
|---|---|
open(ruta, modo) |
Abre el archivo o dispositivo y devuelve un descriptor (entero) |
read(fd, buffer, n) |
Lee hasta n bytes desde fd al buffer |
write(fd, buffer, n) |
Escribe n bytes desde buffer hacia fd |
close(fd) |
Cierra el descriptor y libera recursos |
Tabla 3: Llamadas al sistema básicas de E/S en Unix.
Un descriptor de archivo (file descriptor, fd) es un entero pequeño que identifica al recurso abierto dentro del proceso. Por convención, todo proceso arranca con tres descriptores ya abiertos:
0: entrada estándar (stdin).1: salida estándar (stdout).2: salida de error (stderr).
7.5.2 Ejemplo: copia de un archivo en C
int origen = open("entrada.txt", O_RDONLY);
int destino = open("salida.txt", O_WRONLY | O_CREAT, 0644);
char buffer[4096];
ssize_t n;
while ((n = read(origen, buffer, sizeof(buffer))) > 0) {
write(destino, buffer, n);
}
close(origen);
close(destino);El programa no sabe ni le importa si los archivos están en un SSD, un pendrive o un sistema de archivos remoto: el kernel resuelve esa diferencia.
7.5.3 Capas atravesadas
Cuando una aplicación llama a read, la solicitud atraviesa varias capas hasta el hardware:
flowchart TB
A["Aplicación<br>(read, write)"] --> B["Biblioteca C<br>(libc)"]
B --> C["Llamada al sistema<br>(kernel)"]
C --> D["Subsistema de E/S<br>genérico"]
D --> E["Driver del<br>dispositivo"]
E --> F["Controlador<br>(hardware)"]
F --> G["Dispositivo"]
Figura 2: Capas que atraviesa una operación de E/S desde la aplicación hasta el hardware.
Cada capa esconde la complejidad de la siguiente. El driver es la pieza que conoce los detalles del controlador; el resto del kernel solo le habla por una interfaz estándar.
7.6 Scheduling de E/S
Cuando varios procesos solicitan operaciones sobre el mismo dispositivo a la vez, el SO debe decidir en qué orden atenderlas. Esa decisión se llama scheduling de E/S. A diferencia del scheduling de CPU —que reparte instantes de procesador entre procesos—, el scheduling de E/S reparte el acceso a un recurso compartido (típicamente un disco).
El SO mantiene una cola de solicitudes por cada dispositivo. Al llegar una nueva operación se encola; cuando el dispositivo queda libre, el scheduler elige cuál atender primero.
Los objetivos pueden entrar en tensión:
- Latencia mínima: que ninguna solicitud espere demasiado.
- Throughput máximo: atender la mayor cantidad de operaciones por segundo.
- Equidad: que ningún proceso quede postergado indefinidamente.
- Prioridades: respetar la urgencia relativa (por ejemplo, una solicitud de paginación del kernel suele tener prioridad sobre una lectura de usuario).
Un buen algoritmo de scheduling de disco aprovecha la geometría del dispositivo —dónde está el cabezal, qué bloque queda más cerca— para reducir el movimiento mecánico, que es la operación más lenta de un disco rígido.
7.7 Buffering, Caching y Spooling
El SO no entrega los datos directamente del dispositivo a la aplicación: los almacena temporalmente en regiones de memoria que cumplen distintos propósitos. Tres técnicas comparten ese principio pero responden a problemas distintos: buffering, caching y spooling.
7.7.1 Buffering
Un buffer es una región de memoria que sirve de punto de paso entre dos partes que trabajan a velocidades distintas o en unidades distintas. El productor deposita datos; el consumidor los retira cuando puede. Tres motivos habituales:
- Diferencia de velocidad: un disco entrega un bloque en milisegundos; la aplicación lo procesa en microsegundos. El buffer permite que el disco siga escribiendo el siguiente bloque mientras la aplicación procesa el actual.
- Diferencia de tamaño de transferencia: el disco trabaja con bloques de 4 KB; la aplicación pide de a 1 KB. El kernel lee 4 KB al buffer y le entrega los 1 KB a la aplicación, ahorrando lecturas físicas.
- Semántica de copia: si la aplicación pasa datos para escribir y luego los modifica, el buffer guarda una copia estable que el dispositivo escribe más tarde sin riesgo de inconsistencias.
7.7.2 Caching
Un caché es una copia local rápida de datos cuyo origen es lento o lejano, con el propósito de acelerar accesos repetidos. Si un bloque ya está en el caché, no hace falta volver al dispositivo.
Linux mantiene un page cache en RAM con bloques recientemente leídos del disco: si la aplicación vuelve a leer el mismo archivo, el segundo read se sirve desde RAM y no toca el disco.
Note
Buffering vs. caching. El buffer es un punto de paso obligatorio: los datos están ahí porque tienen que pasar por algún lado. El caché es una optimización oportunista: los datos están ahí porque podrían volver a pedirse. Una misma región de memoria puede cumplir ambos roles a la vez.
7.7.3 Spooling
Spooling (Simultaneous Peripheral Operations On-Line) es una técnica para dispositivos que no pueden compartirse simultáneamente entre varios procesos, como las impresoras. Si dos procesos imprimieran a la vez, las páginas se mezclarían.
La solución: el SO guarda la salida de cada proceso en un archivo (spool) y un demonio los manda a la impresora uno por uno en orden. Los procesos creen que imprimieron al instante; la impresora ve un único cliente ordenado.
| Técnica | Propósito | Ejemplo |
|---|---|---|
| Buffering | Adaptar velocidades y tamaños distintos | Lectura de disco bloque a bloque |
| Caching | Acelerar accesos repetidos | Page cache de Linux |
| Spooling | Serializar acceso a un dispositivo no compartible | Cola de impresión |
Tabla 4: Buffering, caching y spooling: tres técnicas, tres problemas.
7.8 Algoritmos de Scheduling de Disco
En un disco rígido tradicional, el dato se localiza moviendo un cabezal sobre los platos giratorios. Ese movimiento mecánico —seek— es lentísimo comparado con cualquier operación electrónica: típicamente entre 5 y 15 ms. Cuando hay varias solicitudes pendientes, el orden en que se atienden determina cuánto se mueve el cabezal en total.
Los algoritmos clásicos asumen una cola de solicitudes con números de pista (cilindro) y deciden el orden de atención.
7.8.1 FCFS (First-Come, First-Served)
Atiende las solicitudes en el orden de llegada. Es el más simple y más justo: nadie espera más de lo razonable. Pero ignora la geometría: si las solicitudes vienen en pistas muy alejadas, el cabezal se mueve mucho y el rendimiento cae.
7.8.2 SSTF (Shortest Seek Time First)
Siempre elige la solicitud cuya pista está más cerca de la posición actual del cabezal. Minimiza el movimiento medio en cada paso, pero puede provocar inanición: una solicitud en una pista lejana podría no atenderse jamás si siguen llegando solicitudes cercanas.
7.8.3 SCAN (algoritmo del elevador)
El cabezal se mueve en una dirección hasta llegar al extremo del disco, atendiendo en el camino todas las solicitudes que encuentre. Al llegar al extremo, invierte la dirección y hace lo mismo hacia el otro lado. Su comportamiento recuerda al de un ascensor que sube y baja recogiendo pasajeros, de allí su nombre.
Resuelve el problema de inanición de SSTF: ninguna solicitud espera más de un recorrido completo.
7.8.4 LOOK
Variante práctica de SCAN: el cabezal no llega al extremo físico del disco; invierte la dirección en cuanto ya no quedan solicitudes pendientes hacia ese lado. Es levemente más rápido que SCAN puro porque ahorra el viaje hasta el borde.
7.8.5 C-SCAN (Circular SCAN)
Como SCAN, pero al llegar al extremo el cabezal salta directamente al inicio sin atender solicitudes durante el retorno; luego comienza otra pasada en la misma dirección. Así, el tiempo de espera entre dos atenciones de la misma pista resulta más uniforme: en SCAN puro, las pistas cercanas a los extremos se atendían dos veces seguidas, mientras que las del medio esperaban un ciclo completo.
7.8.6 Comparativa
| Algoritmo | Idea | Ventaja | Limitación |
|---|---|---|---|
| FCFS | Orden de llegada | Justo y trivial | Puede causar mucho movimiento |
| SSTF | El más cercano primero | Buen rendimiento medio | Inanición de pistas lejanas |
| SCAN | Barrido de extremo a extremo | Sin inanición | Espera desigual según posición |
| LOOK | SCAN sin llegar al extremo | Más eficiente que SCAN | Misma irregularidad de espera |
| C-SCAN | Barrido en una sola dirección | Espera uniforme | Salta sin atender en el retorno |
Tabla 5: Algoritmos clásicos de scheduling de disco.
Tip
Vigencia hoy. En discos SSD no hay cabezal que mover: cualquier bloque está a la misma distancia del controlador. Los algoritmos basados en geometría (SSTF, SCAN, LOOK, C-SCAN) pierden buena parte de su sentido. Los SSD usan schedulers más simples (none, mq-deadline en Linux) cuyo objetivo es la equidad y la prioridad, no el ahorro de seeks.