flowchart LR
subgraph L[Espacio lógico]
P0[Página 0]
P1[Página 1]
P2[Página 2]
end
subgraph T[Tabla de páginas]
T0["0 → 5"]
T1["1 → 2"]
T2["2 → 7"]
end
subgraph F[Memoria física]
F2[Marco 2]
F5[Marco 5]
F7[Marco 7]
end
P0 --> T0 --> F5
P1 --> T1 --> F2
P2 --> T2 --> F7
6 La Administración de Memoria en Sistemas Operativos
La administración de memoria es uno de los pilares del diseño de sistemas operativos: su tarea es repartir la memoria física entre los procesos activos, garantizando que cada uno acceda solo a lo que le corresponde y que el espacio disponible se aproveche sin desperdicios.
6.1 Objetivos de Aprendizaje
- Explicar las políticas clásicas de administración de memoria: monitor residente, partición estática y partición dinámica.
- Comprender la resolución de direcciones lógicas a físicas como mecanismo base de la gestión de memoria.
- Distinguir paginación y segmentación, y su combinación en la paginación segmentada.
- Describir la carga y el enlace dinámico, y el rol de las librerías compartidas.
- Usar comandos de terminal para inspeccionar librerías y memoria en un sistema real.
- Explicar los mecanismos de memoria virtual: overlays y paginación bajo demanda.
- Comprender los conceptos de localidad de referencia, espacio de trabajo e hiperpaginado.
6.2 Políticas Clásicas de Administración de Memoria
6.2.1 Monitor residente
El monitor residente operaba bajo un principio de separación estricta entre el espacio del sistema y el del usuario. Utilizaba un registro de “cerca” (fence register) para delimitar ambas zonas, verificando cada acceso a memoria mediante hardware o software.
Ejemplo didáctico. Imaginemos una biblioteca donde el bibliotecario (monitor) ocupa siempre las primeras estanterías. Los usuarios (programas) solo pueden acceder a las secciones posteriores, y cualquier intento de entrar al área reservada genera una alerta.
Limitaciones:
- Fragmentación interna: si el programa del usuario requería menos espacio que la partición asignada, el excedente se desperdiciaba.
- Rigidez: la ubicación del monitor no podía modificarse durante la ejecución, dificultando la escalabilidad.
6.2.2 Partición estática
En este esquema, la memoria se divide en regiones de tamaño fijo antes de la ejecución de los procesos. Cada partición alberga un único programa, y el sistema operativo emplea algoritmos simples para asignarlas:
- Primer ajuste (first-fit): asigna la primera partición libre que cumpla con el tamaño requerido.
- Mejor ajuste (best-fit): busca la partición más pequeña que pueda contener al proceso.
- Peor ajuste (worst-fit): utiliza la partición más grande disponible, dejando espacio residual para futuros procesos.
Caso de estudio. Un sistema con particiones de 64 KB, 128 KB y 256 KB. Si un proceso de 100 KB solicita memoria:
- Primer ajuste: ocupa la partición de 128 KB, desperdiciando 28 KB.
- Mejor ajuste: usa la misma partición de 128 KB.
- Peor ajuste: asigna la de 256 KB, generando 156 KB no utilizados.
Problemas inherentes:
- Fragmentación interna: espacio no utilizado dentro de particiones asignadas.
- Subutilización: procesos pequeños ocupan particiones grandes, reduciendo la capacidad de multiprogramación.
6.2.3 Partición dinámica
Para superar las limitaciones de la partición estática, se introdujo la asignación dinámica, donde las particiones se crean en tiempo de ejecución según las necesidades de cada proceso. Este enfoque requiere estructuras de datos complejas (tablas de huecos libres) y algoritmos de coalescencia para fusionar espacios adyacentes liberados.
Mecanismo operativo:
- Solicitud de memoria: el proceso indica cuánto espacio necesita.
- Búsqueda de hueco: el sistema identifica un bloque libre usando algoritmos como:
- Next-fit: continúa buscando desde la última asignación.
- Buddy system: divide la memoria en bloques de potencias de dos para facilitar la coalescencia.
- Asignación y actualización: se marca el espacio como ocupado y se actualizan las tablas de gestión.
Warning
Fragmentación externa. Con el tiempo, la memoria libre queda dispersa en pequeños huecos entre particiones ocupadas. Puede haber memoria libre suficiente para un nuevo proceso, pero no en un bloque contiguo. La solución clásica —compactación— es costosa porque exige mover procesos en tiempo de ejecución.
6.2.4 Comparativa entre enfoques clásicos
| Aspecto | Monitor residente | Partición estática | Partición dinámica |
|---|---|---|---|
| Flexibilidad | Baja | Moderada | Alta |
| Fragmentación | Interna | Interna | Externa |
| Complejidad | Simple | Moderada | Alta |
| Multiprogramación | No soportada | Limitada | Soportada |
| Ejemplos históricos | IBM 1401 | OS/360 | UNIX temprano |
Tabla 1: Características comparativas de las políticas clásicas de gestión de memoria.
6.3 Resolución de Direcciones Lógicas a Físicas
Cuando un programa se compila no se sabe en qué posición de la memoria física vivirá durante su ejecución. Por eso el código generado usa direcciones lógicas (también llamadas virtuales): números independientes de la ubicación real, definidos respecto al inicio del programa.
En cada acceso a memoria, el hardware debe convertir esa dirección lógica en una dirección física —la posición real de RAM donde está el dato—. Este paso se llama resolución o traducción de direcciones, y ocurre en cada lectura o escritura, sin que el programa lo perciba.
La encargada de la traducción es la MMU (Memory Management Unit), un componente integrado en el procesador. La MMU consulta estructuras que mantiene el sistema operativo:
- Tabla de páginas: traduce bajo el esquema de paginación.
- Tabla de segmentos: traduce bajo el esquema de segmentación.
- Combinación de ambas: en la paginación segmentada.
Ejemplo numérico. Un sistema con páginas de 4 KB (4096 bytes). Un proceso accede a la dirección lógica que corresponde a la página 2, desplazamiento 100. La tabla de páginas del proceso indica que la página 2 está alojada en el marco 7 de la memoria física. La MMU calcula la dirección física como:
\[ \text{dirección física} = (\text{marco} \times \text{tamaño de página}) + \text{desplazamiento} = 7 \times 4096 + 100 = 28\,772 \]
El programa nunca trabaja con el número 28 772; sigue viendo “página 2, posición 100”. La traducción es invisible.
Tip
Analogía. Pensemos en los casilleros de una facultad. Cada estudiante recibe un número de casillero (dirección lógica) que es fácil de recordar y nunca cambia. El conserje mantiene una libreta (tabla de páginas) que dice dónde está físicamente cada casillero —en qué pasillo y qué pared—. El estudiante nunca necesita saber la ubicación real: pide “el casillero 27” y el conserje lo lleva al lugar correcto. Si la facultad reorganiza el edificio, solo cambia la libreta; el número del casillero sigue siendo el mismo.
Esta indirección hardware-software es el mecanismo base sobre el que se apoyan todos los esquemas modernos de gestión de memoria: la protección entre procesos, la memoria virtual y la compartición de bibliotecas dependen de que la traducción ocurra de forma transparente y a la velocidad del acceso.
Note
Idea clave. Sin resolución de direcciones, cada programa tendría que conocer su ubicación exacta en RAM y no podría coexistir con otros. La traducción transparente es lo que permite que múltiples procesos compartan la memoria física sin conflictos.
6.4 Paginación, Segmentación y Paginación Segmentada
6.4.1 Paginación
La paginación es una técnica de gestión de memoria que permite dividir un programa en bloques de tamaño fijo llamados páginas, los cuales pueden ubicarse en diferentes partes de la memoria física, sin necesidad de estar contiguos. La memoria física, a su vez, se divide en bloques del mismo tamaño denominados marcos (frames).
Antes de ejecutar un programa, el sistema realiza los siguientes pasos:
- Calcula el número de páginas necesarias, según el tamaño total del programa.
- Identifica los marcos de memoria disponibles.
- Carga cada página del programa en uno de esos marcos disponibles.
Este enfoque permite que un programa sea cargado en regiones dispersas de la memoria, evitando la necesidad de bloques contiguos y eliminando la fragmentación externa. Sin embargo, persiste una pequeña fragmentación interna en la última página, que rara vez se llena por completo.
Figura 1: Traducción de páginas a marcos mediante la tabla de páginas.
Tip
Ejemplo concreto. Un programa de 10 KB en un sistema con páginas de 4 KB ocupa 3 páginas. La última página solo usa 2 KB reales: los otros 2 KB constituyen fragmentación interna, pero son una pérdida acotada y predecible.
6.4.2 Segmentación
La segmentación es un método de gestión de memoria donde un programa se divide en partes lógicas de diferente tamaño, llamadas segmentos. A diferencia de la paginación —donde todo se divide en bloques iguales—, en segmentación cada parte puede tener un tamaño distinto, según la función que cumpla en el programa.
Un programa no es una sola cosa continua: normalmente está compuesto por varias secciones, como:
- El programa principal (la función
main). - Varias subrutinas o funciones auxiliares.
- Un bloque de datos globales.
- Una pila para las llamadas de funciones.
Cada una de estas partes se puede convertir en un segmento. Por ejemplo:
- Segmento 0: código principal (
main). - Segmento 1: subrutina A.
- Segmento 2: subrutina B.
- Segmento 3: datos globales.
- Segmento 4: pila.
Cada segmento se carga en una parte de la memoria principal, pero no necesariamente uno al lado del otro. El sistema operativo lleva un registro de cada segmento mediante una tabla de segmentos, que guarda dos datos importantes:
- La dirección base: dónde empieza ese segmento en memoria.
- El límite: cuánto ocupa (es decir, su tamaño).
Una dirección lógica bajo segmentación tiene el formato (segmento, desplazamiento). El sistema verifica que el desplazamiento sea menor que el límite; de lo contrario genera una violación de segmento (el conocido segmentation fault).
Note
Paginación vs. segmentación. La paginación es una división física (tamaños iguales, invisible al programador). La segmentación es una división lógica (refleja la estructura del programa). Cada una resuelve un problema distinto, y por eso surge la pregunta natural: ¿se pueden combinar?
6.4.3 Paginación segmentada
Paginación y segmentación resuelven problemas distintos: la paginación elimina la fragmentación externa pero ignora la estructura lógica del programa; la segmentación respeta esa estructura pero sufre de fragmentación externa. La paginación segmentada combina ambas: el programa se divide primero en segmentos lógicos (código, datos, pila…) y cada segmento se divide internamente en páginas de tamaño fijo.
Con esta combinación se obtiene lo mejor de los dos enfoques:
- La vista lógica del programa se conserva: un segmento por componente.
- La memoria física se llena con páginas, por lo que no hay fragmentación externa.
- Segmentos completos —por ejemplo, una librería compartida— se pueden proteger o compartir entre procesos de forma natural.
Ejemplo concreto. Un programa con tres componentes —código (12 KB), datos (6 KB) y pila (8 KB)— en un sistema con páginas de 4 KB queda organizado así:
| Segmento | Tamaño | Páginas | Marcos asignados |
|---|---|---|---|
| 0 — código | 12 KB | 3 | 7, 2, 9 |
| 1 — datos | 6 KB | 2 | 5, 11 (última con 2 KB sin usar) |
| 2 — pila | 8 KB | 2 | 1, 3 |
Cada segmento conserva su identidad lógica —el programador sigue viendo “código”, “datos” y “pila”— pero físicamente queda repartido en marcos no contiguos de la RAM. Una dirección lógica tiene la forma (segmento, página, desplazamiento): la MMU usa el primer número para elegir tabla de páginas, el segundo para elegir marco, y el tercero para ubicar el byte dentro del marco.
Fue el esquema dominante en las arquitecturas Intel x86 clásicas (del 80286 en adelante). Hoy, en x86-64, los sistemas operativos modernos (Linux, Windows, macOS) tratan los segmentos como planos —cubren todo el espacio— y usan paginación pura.
6.5 Carga y Enlace Dinámico
Tradicionalmente, un programa tenía que estar completo en memoria antes de comenzar a ejecutarse: todas sus funciones y todas las librerías que usa se copiaban dentro del ejecutable y se cargaban de una sola vez. Las técnicas de carga dinámica y enlace dinámico rompen con ese esquema y hacen el uso de la memoria mucho más eficiente.
6.5.1 Carga dinámica
La carga dinámica permite a un programa incorporar a memoria solo las partes de su código que realmente necesita en cada momento. Un módulo no se carga al iniciar el proceso, sino cuando el flujo de ejecución lo requiere; si no se usa, nunca ocupa memoria.
Ejemplo. Una aplicación de edición de archivos tiene funciones para exportar a PDF, a Word y a imagen. Si el usuario solo exporta a PDF, únicamente el módulo de PDF se carga en memoria. Los otros dos nunca entran a RAM aunque el ejecutable los “conozca”.
Este mecanismo es la base de los plugins en navegadores, editores de texto e IDEs: el programa principal carga módulos opcionales en tiempo de ejecución según lo que el usuario active.
6.5.2 Enlace dinámico
El enlace dinámico ocurre cuando el programa se carga en memoria: el sistema operativo busca las bibliotecas compartidas que el programa necesita y las conecta, sin que esas bibliotecas estén copiadas dentro del ejecutable. El ejecutable solo contiene referencias (nombres) a las librerías externas; el sistema resuelve esas referencias al arrancar.
Esto trae dos beneficios directos:
- Varios programas comparten una sola copia de la librería en memoria.
- Si se corrige o actualiza la librería, todos los programas que la usan se benefician automáticamente, sin recompilar.
El comando ldd <ejecutable> permite ver las librerías dinámicas que un programa necesita y dónde las resolvió el sistema. En la próxima sección lo usaremos como herramienta de inspección.
6.5.3 Librerías: estáticas vs. dinámicas
Una librería (o biblioteca) es un conjunto de funciones ya compiladas y reutilizables. Hay dos formas de incorporarla a un programa:
| Característica | Librería estática | Librería dinámica |
|---|---|---|
| Extensión | .a (Linux), .lib (Windows) |
.so (Linux), .dll (Windows), .dylib (macOS) |
| Momento de enlace | Al compilar | Al cargar o durante la ejecución |
| Tamaño del ejecutable | Grande (copia la librería adentro) | Pequeño (solo referencias) |
| Compartición en RAM | No: cada proceso tiene su copia | Sí: una sola copia para todos |
| Actualización | Hay que recompilar el programa | Se reemplaza el archivo de librería |
| Dependencia en ejecución | Ninguna | El .so/.dll debe estar presente |
Ejemplo contundente. La librería libc de GNU/Linux (libc.so.6) es usada por casi todos los procesos del sistema. Si fuera estática, cada proceso tendría su propia copia —unos 2 MB por programa— sumando cientos de megabytes duplicados en RAM. Gracias al enlace dinámico, una sola copia en memoria atiende a todos los procesos simultáneamente.
Tip
¿Cuándo conviene cada una? Las librerías estáticas sirven cuando se necesita un binario autocontenido (ejecutable portable, sistema embebido sin dependencias externas). Las dinámicas dominan en sistemas de propósito general: ahorran memoria y permiten parchar fallos de seguridad sin recompilar los programas.
6.6 Inspección de Memoria y Librerías desde la Terminal
Los conceptos vistos hasta aquí pueden observarse directamente en un sistema real. Linux expone la información de memoria y bibliotecas a través del pseudo-sistema /proc y de utilidades de línea de comandos.
6.6.1 Bibliotecas dinámicas de un ejecutable
ldd /bin/lsLista las bibliotecas dinámicas (.so) que un ejecutable necesita y las rutas donde el sistema las resolvió. Permite observar el enlace dinámico en acción. Salida típica:
linux-vdso.so.1 (0x00007ffd5e3b3000)
libselinux.so.1 => /lib/x86_64-linux-gnu/libselinux.so.1 (0x00007f8b2c4a0000)
libc.so.6 => /lib/x86_64-linux-gnu/libc.so.6 (0x00007f8b2c270000)
/lib64/ld-linux-x86-64.so.2 (0x00007f8b2c5d0000)Cada línea muestra el nombre de la librería, la ruta del archivo .so y la dirección donde quedó cargada. libc.so.6 aparece aquí porque casi todos los binarios la enlazan.
nm -D /usr/lib/x86_64-linux-gnu/libc.so.6 | headMuestra los símbolos exportados por una librería: las funciones que ofrece a los programas que la enlacen. Salida típica:
00000000000a3320 T abort
0000000000059780 T accept
00000000001275a0 T access
0000000000087a40 T atoi
0000000000087b20 T atolLa letra T indica que el símbolo es una función exportada (en la sección de texto). El número a la izquierda es su desplazamiento dentro de la librería.
6.6.2 Mapa de memoria de un proceso
cat /proc/$$/mapsImprime el espacio de direcciones del shell actual. Cada línea es una región de memoria con su rango de direcciones, sus permisos (r, w, x) y el archivo de respaldo: el ejecutable, una librería compartida o regiones especiales como [heap] y [stack]. Salida típica (recortada):
560a8c4d8000-560a8c4f3000 r--p /usr/bin/bash
560a8c4f3000-560a8c5e0000 r-xp /usr/bin/bash
7f3e9c200000-7f3e9c228000 r--p /lib/x86_64-linux-gnu/libc.so.6
7f3e9c228000-7f3e9c3b0000 r-xp /lib/x86_64-linux-gnu/libc.so.6
560a8d5c1000-560a8d5e3000 rw-p [heap]
7ffd5e394000-7ffd5e3b5000 rw-p [stack]Se distinguen claramente las regiones del ejecutable, las librerías compartidas, el heap (memoria dinámica) y la pila.
pmap -x <PID>Versión resumida del mismo mapa, agrupada por región. Útil para ver el tamaño residente de cada librería compartida en un proceso concreto.
6.6.3 Estado global de la memoria
free -hResume RAM total, usada, libre, buffers/caché y swap:
total used free shared buff/cache available
Mem: 7.7Gi 2.1Gi 3.0Gi 95Mi 2.6Gi 5.3Gi
Swap: 2.0Gi 0B 2.0GiSwap: used = 0B indica que el sistema todavía no necesitó disco para sostener procesos. Un valor distinto de cero ya implica memoria virtual en uso real.
vmstat 1 5Cinco muestras de un segundo con la actividad de paginación:
procs -----memory---- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free si so bi bo in cs us sy id wa st
1 0 0 3.1Gi 0 0 24 18 450 920 3 1 96 0 0
0 0 0 3.1Gi 0 0 0 0 410 880 2 1 97 0 0Las columnas si y so indican páginas entrando y saliendo de swap. Si so es distinta de cero de forma sostenida, el sistema está usando swap activamente —síntoma típico de hiperpaginado incipiente—.
6.7 Memoria Virtual
Hasta aquí supusimos que, para ejecutar un programa, todo el programa debe estar en memoria física. La memoria virtual rompe esa suposición: permite que un proceso trabaje con un espacio de direcciones mayor que la RAM disponible, manteniendo en memoria solo las partes que se están usando en ese momento y guardando el resto en disco (en un área llamada swap o archivo de paginación).
6.7.1 Overlays
Antes de que el hardware soportara memoria virtual, los programadores resolvían el problema “programa más grande que la memoria” con overlays (superposiciones): el programador dividía manualmente el programa en módulos que no se necesitan al mismo tiempo, y diseñaba el código para que al entrar uno sobrescribiera al anterior en la misma zona de memoria.
Ejemplo. Un compilador de dos pasadas:
- Fase 1: análisis léxico y sintáctico (módulo A).
- Fase 2: generación de código (módulo B).
Ambos nunca se ejecutan a la vez, así que ocupan el mismo lugar en RAM. El programador escribía la instrucción exacta para cargar B sobre el área que antes ocupaba A.
flowchart TB
subgraph M[Memoria física limitada]
R[Rutinas comunes]
O["Área de overlay<br>(reutilizable)"]
end
A[Fase 1: análisis] -.carga.-> O
B[Fase 2: codegen] -.reemplaza a.-> O
Figura 2: Un área de memoria compartida por varios overlays que se turnan.
El gran problema: la división es responsabilidad del programador, no del sistema. Es frágil y no escala a programas modernos. Los overlays fueron reemplazados por memoria virtual, que automatiza todo el proceso sin que el programador tenga que intervenir.
6.7.2 Paginación bajo demanda
La paginación bajo demanda (demand paging) es la técnica que implementa memoria virtual en los sistemas actuales. Su idea central es simple:
Una página se carga en RAM solo cuando el proceso intenta acceder a ella.
Al iniciar un proceso, el sistema no copia todo su espacio de direcciones a memoria: arranca con lo mínimo y va trayendo páginas desde disco a medida que el programa las necesita.
Ejemplo concreto. Un editor de texto cuyo ejecutable y librerías ocupan unos 200 MB en disco puede arrancar cargando solo unas pocas páginas iniciales —del orden de 100 KB en RAM—. Las páginas restantes (funciones que el usuario aún no invocó, recursos gráficos no visibles, traducciones en idiomas no seleccionados) se traen al RAM únicamente cuando el flujo de ejecución las alcanza, y muchas no se cargan jamás durante la sesión.
¿Cómo lo detecta el sistema? Cada entrada de la tabla de páginas tiene un bit válida / inválida. Si el proceso accede a una página marcada como “no está en RAM”, la MMU genera una interrupción llamada fallo de página (page fault). El sistema operativo atiende el fallo: localiza la página en el swap, la carga en un marco libre (o desaloja uno si no hay libres), actualiza la tabla de páginas y reanuda la instrucción como si nada hubiera pasado.
flowchart LR
A[Proceso accede<br>a página P] --> B{¿P está<br>en RAM?}
B -- Sí --> C[Acceso normal]
B -- No --> D["Fallo de página<br>(page fault)"]
D --> E[SO trae P<br>desde disco]
E --> C
Figura 3: Flujo básico ante un fallo de página.
¿Qué logra la paginación bajo demanda?
- Ejecutar programas más grandes que la RAM (el exceso vive en disco).
- Arrancar rápido: el proceso empieza sin cargar todo de golpe.
- Mayor multiprogramación: caben más procesos activos al mismo tiempo.
6.8 Localidad de Referencia, Espacio de Trabajo e Hiperpaginado
6.8.1 Principio de localidad
Los programas no acceden a memoria de forma aleatoria: concentran sus accesos en un subconjunto pequeño de páginas durante cada fase de ejecución. Esta propiedad —el principio de localidad de referencia— es el fundamento que hace posible la paginación bajo demanda.
Existen dos formas complementarias:
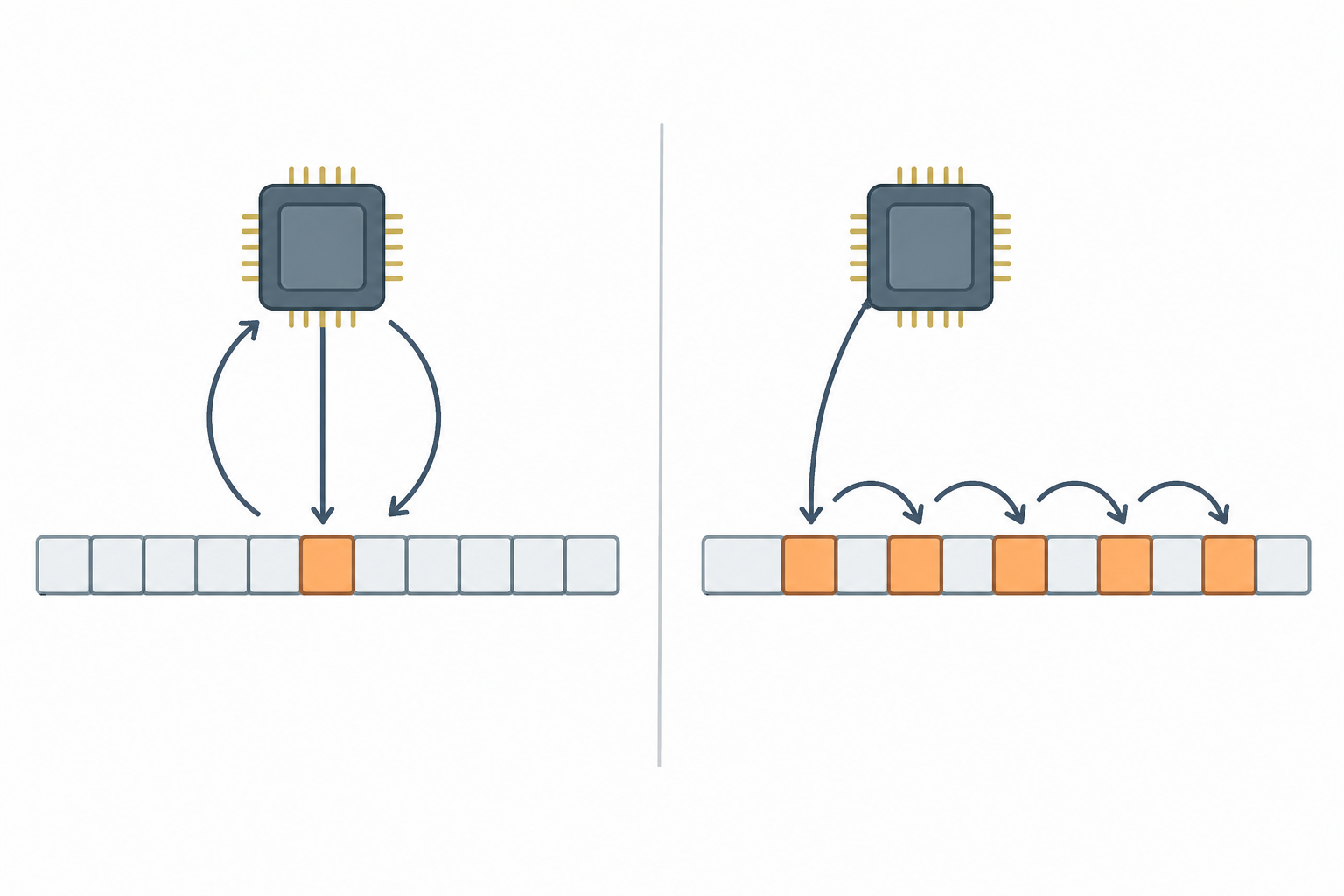
- Localidad temporal: una dirección accedida ahora probablemente se acceda de nuevo pronto. Ejemplo: las variables de control de un bucle se leen en cada iteración.
- Localidad espacial: acceder a una dirección aumenta la probabilidad de acceder a direcciones vecinas. Ejemplo: recorrer un arreglo de izquierda a derecha lee páginas contiguas.
Note
Idea clave. Sin localidad, cada referencia tocaría una página distinta y la tasa de fallos haría que la paginación bajo demanda fuese inutilizable en la práctica.
6.8.2 Espacio de trabajo
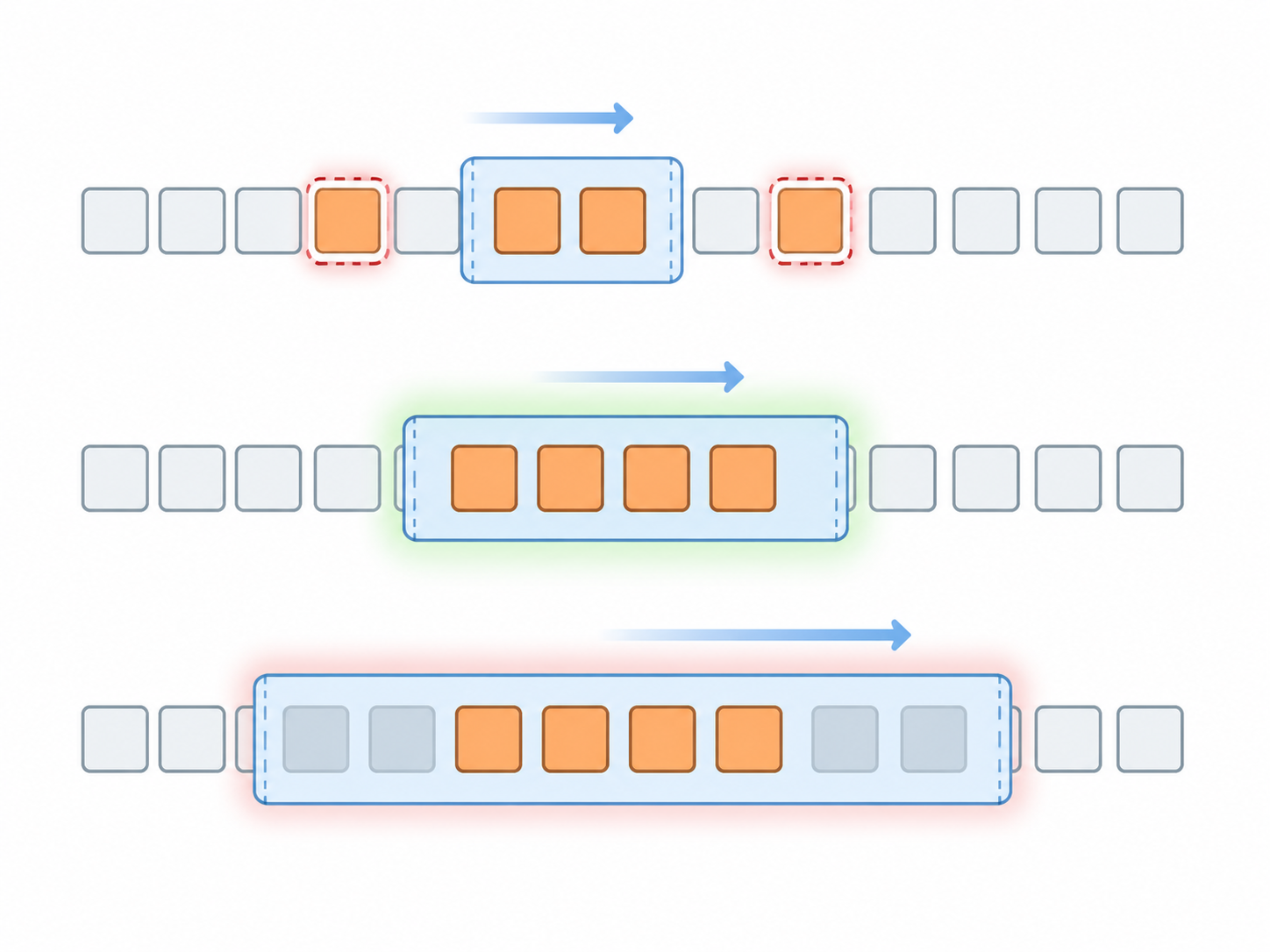
El modelo del espacio de trabajo (working set), propuesto por Peter Denning, responde a una pregunta práctica: ¿cuántas páginas necesita mantener en RAM un proceso para no generar fallos constantemente?
El SO observa cuáles páginas usó el proceso en un intervalo reciente —la ventana del espacio de trabajo—. Si la ventana es demasiado corta, el SO no ve todas las páginas activas y expulsa páginas que pronto se necesitarán de nuevo. Si es demasiado larga, retiene páginas de fases pasadas que ya no se usan.
Tip
Analogía. Como un estudiante que prepara un examen: si solo repasa los últimos cinco minutos de apuntes (ventana corta), olvida material importante; si repasa todo el semestre (ventana larga), pierde tiempo con temas que no entran.
6.8.3 Hiperpaginado
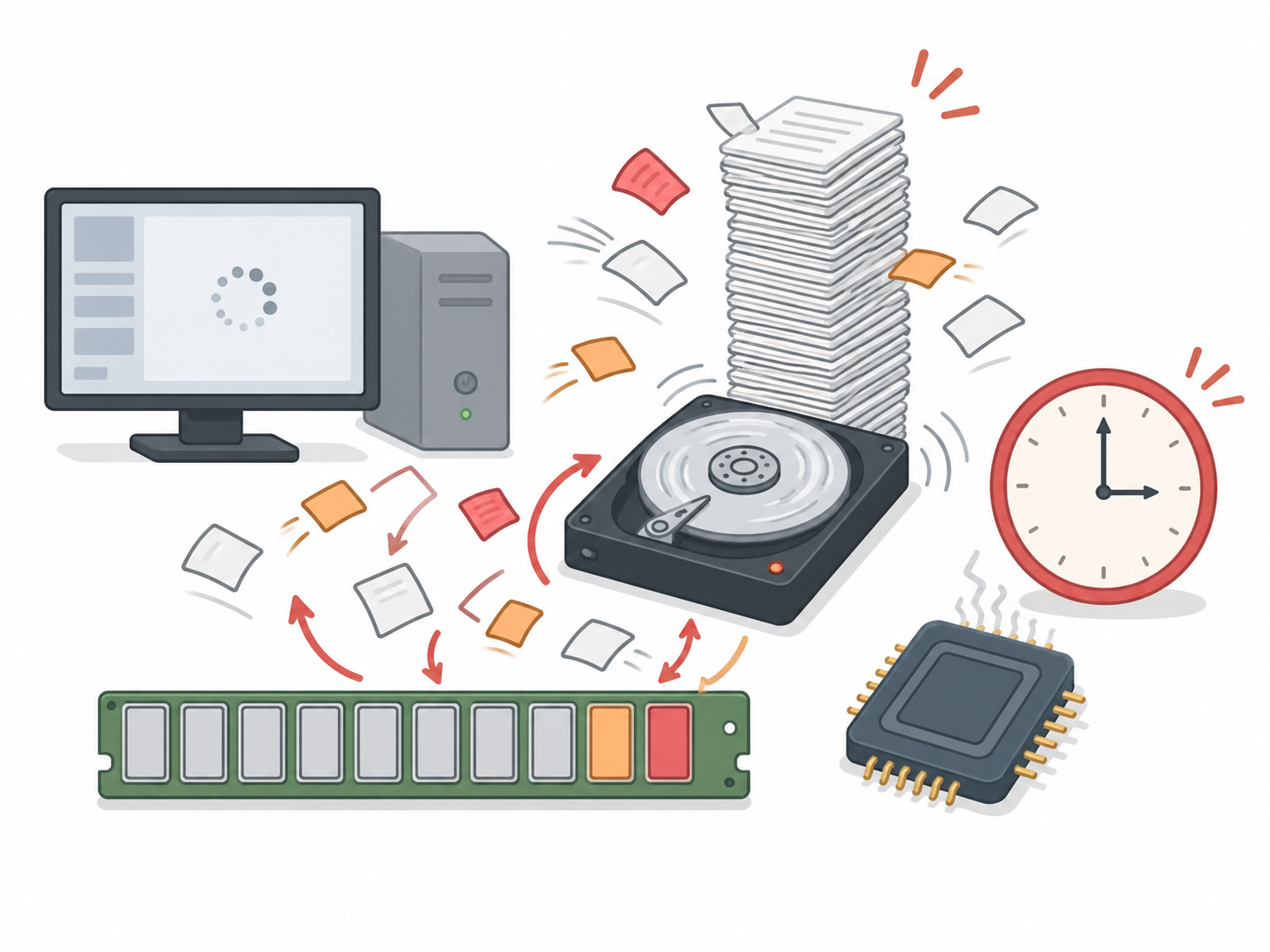
El hiperpaginado (thrashing) ocurre cuando el sistema dedica más tiempo a intercambiar páginas entre RAM y disco que a ejecutar instrucciones útiles. La utilización de la CPU cae hacia cero pese a haber procesos activos.
El mecanismo de colapso es un círculo vicioso: la CPU baja, el planificador agrega procesos para mantenerla ocupada, esos procesos roban marcos a los demás, todos sufren más fallos de página, el disco se satura y la CPU queda esperando I/O. Cuanto más actúa el planificador, peor se vuelve la situación.
flowchart LR
A["CPU baja"] --> B["SO agrega<br>procesos"]
B --> C["Procesos pierden<br>marcos"]
C --> D["Más fallos<br>de página"]
D --> E["Disco<br>saturado"]
E --> A
Figura 4: Espiral del hiperpaginado — cada acción correctiva empeora la situación.
Warning
Causa raíz. El hiperpaginado surge del exceso de multiprogramación: el sistema tiene más procesos activos de los que puede sostener con la RAM disponible.